Natural-Language Search Over Image Libraries: RAG Architecture
How to make thousands of images searchable in plain language without CLIP: RAG architecture using vision at ingest, hybrid search, and custom retrieval glue.

My company had a marketing asset library with over ten thousand images. Designers scrolled through folders. Ops teams pinged colleagues asking if someone knew where last quarter's campaign photos were. Executives pulled the wrong hero shot for a presentation because the filename said nothing useful.
Nobody could find anything, and the library kept growing.
When I started prototyping a fix, the question I kept coming back to was: why isn't this already solved? The images exist. The questions people ask aren't complicated: "show me product shots with blue backgrounds," "find images from our Paris campaign," "what do we have that shows people working on laptops?" These are simple questions. The problem is there's no semantic layer connecting the question to the image.
You can't search pixels for intent.
This article is about the architecture I built to fix that. Not a tutorial. I won't walk you through every line of code. What I want to give you is an honest view of the pattern, the decision points, and where it breaks. If you're an architect or tech lead evaluating this kind of system, this is what I wish I'd read before I started.
What About Just Using Image Embeddings?
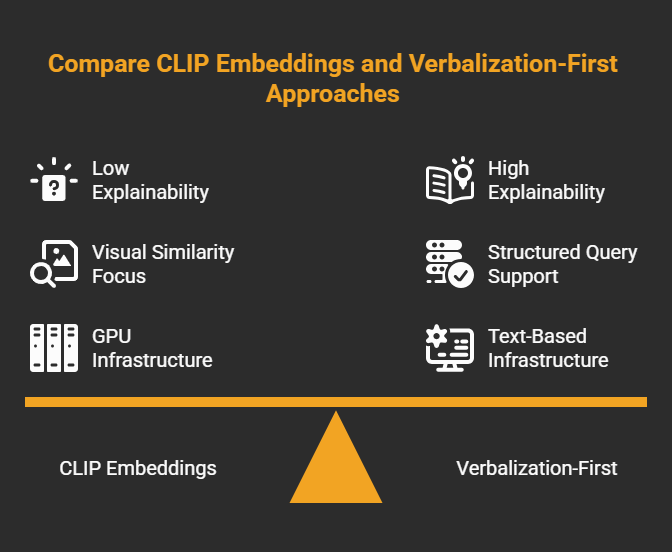
Before going further: the question you'll get from any architect reviewing this is "why not just use CLIP?" Encode every image as a vector, encode the query as a vector, run similarity search. It's a well-understood pattern and there are managed services that handle the inference.
I evaluated it and ruled it out early. Three constraints made the decision straightforward:
Explainability. When a result comes back wrong, you can't tell why. The system matched two high-dimensional vectors. You can't inspect what property triggered the match, and you can't write a rule to fix it.
Structured queries. Users at my company asked things like "find images that mention the word 'sale'" and "show me assets from the product line we launched in Q2." These aren't visual similarity questions. They require text extracted from images, date ranges, product categories. CLIP can't filter on any of those.
Infrastructure overhead. CLIP and its successors need GPU-friendly embedding infra or a managed multimodal embedding service for images. Adding that to a stack that already has a text search index meant introducing a second system to solve what I wanted to keep as one problem.
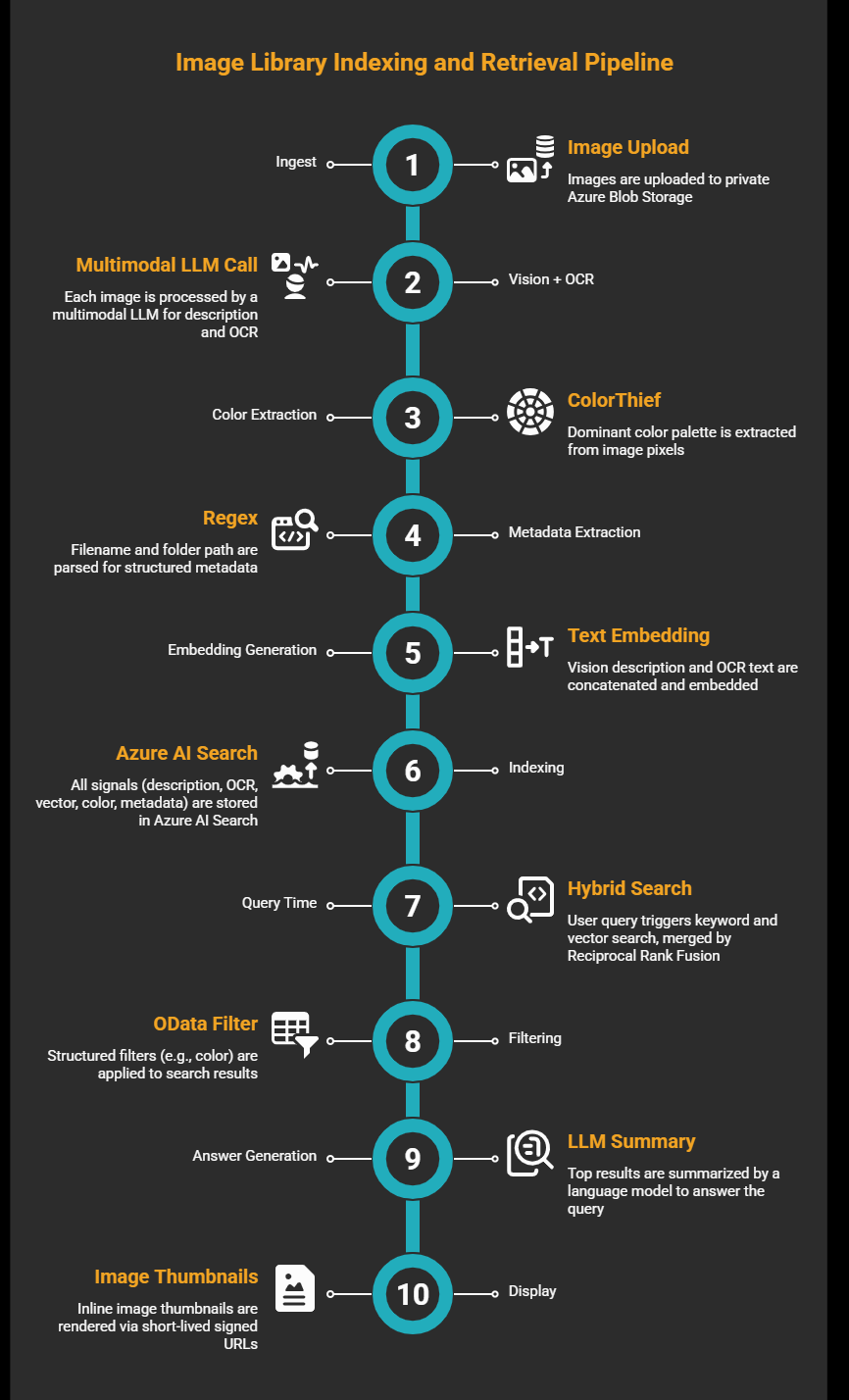
The approach I took treats multimodal as an ingest-time step, not a query-time one. Run vision once when you index. Keep everything downstream as text.
The Core Idea: Verbalize at Ingest, Search with Text
Images aren't unsearchable; they just haven't been translated into a form that search engines understand. The job of the indexing pipeline is to do that translation once, store it, and never repeat it.
When I index an image, I generate three types of signals:
- Visual description + OCR: a single multimodal LLM call (structured output) that returns both a paragraph describing the image (scene, people, objects, context, layout, mood) and any visible text in it (labels, banners, product names, captions, watermarks)
- Color: ColorThief runs on the pixels and extracts the dominant palette, which I map to coarse human-readable names (red, orange, blue, etc.)
- Metadata: regex over the filename and folder path to pull structured signals: campaign name, date, product line, region
All of that lands in a single record in Azure AI Search. Each record holds a text description field, an OCR field, a vector embedding of the concatenated description and OCR, a filterable color names collection, and metadata fields like product and date.
At query time, it's standard text search. The user types a question. The system runs a hybrid query: keyword search and vector search in parallel, merged by Reciprocal Rank Fusion (RRF). If the question implies a filter ("show me blue images"), the system applies a structured OData filter on the color names field. The language model reads the top results and generates a grounded answer. The UI renders inline image thumbnails via short-lived signed URLs (Azure SAS tokens) to the originals.
That's the pipeline. Multimodal at ingest, text index at search. And to be clear about vectors: I do use them: text embeddings let the hybrid query match "campaigns showing teamwork" to a description that says "team collaborating around a table." Vectors rank and surface conceptually similar results within the index. What I'm not doing is embedding the image pixel data directly. The verbalization step is what makes the vector useful; without it, you'd be encoding visual features instead of meaning.
Walking the Pipeline
Storage. Images live in private Azure Blob Storage. The indexer reads them; the UI never serves raw blobs directly. When results come back, the system generates a short-lived SAS (Shared Access Signature) URL for each result; the original stays private. This matters for compliance: image URLs that live forever will end up in chat logs and audit trails.
Vision + OCR, and why it's slow. Each image goes through a single multimodal LLM call that returns a structured output with both a visual description and extracted text. On average, this takes around 10 seconds per image. For a ten-thousand-image library, that's close to 28 hours of sequential processing. Parallelism isn't optional at that scale. I run the indexer with a thread pool and process images concurrently. The good news: you pay this cost once per image, on first ingest and only again when the image changes.
Color and metadata. ColorThief runs on the raw pixels and returns the dominant palette as RGB values. I convert each swatch to a coarse name via HSV analysis: black/white/gray thresholds first, then hue buckets. The result is a collection field per image: ["orange", "white", "gray"]. Metadata extraction is regex against the filename and folder path to pull whatever structured signals your naming conventions encode.
Embeddings. I concatenate the vision description and OCR text, then embed with text-embedding-3-large at 1024 dimensions. The resulting vector goes into the index alongside the text fields.
Index schema. One record per image. Key fields: description (full-text searchable), ocr_text (full-text searchable), description_vector (1024-dim, for semantic search), color_names (collection, filterable), plus metadata fields for product line, region, date, and image path. The schema belongs to the application team, not the infra team. As the product evolves (new metadata fields, new facets), the app team owns the changes without touching storage.
The Part Nobody Tells You: The Retrieval Glue
The model doesn't know how to retrieve anything.
People assume that once you've indexed your data and wired up a language model, the system figures out what to search for. It won't. You have to write explicit logic that:
- Reads the user's question and decides what kind of query to run
- Extracts color mentions, date ranges, keyword terms, and intent from the natural language input
- Constructs the actual hybrid search request: keyword text, vector embedding, OData filters
- Hands the results to the language model with the right context for grounding
In my implementation, a LangGraph agent handles this. When the question contains color words ("blue," "orange"), it builds a filter: color_names/any(c: c eq 'blue'). When the question is conceptual ("campaigns showing teamwork"), it skips the filter and relies on vector similarity. When it's a mix, it runs both.
A real query construction for a color-filtered search looks like this:
# Routing: this is where the complexity lives
color_words = extract_color_words(question) # e.g. ["orange"]
has_keywords = has_keyword_terms(question)
if color_words:
odata_filter = build_color_filter(color_words) # "color_names/any(c: c eq 'orange')"
search_mode = "hybrid"
elif not has_keywords:
odata_filter = None
search_mode = "vector_only" # purely conceptual: "campaigns showing teamwork"
else:
odata_filter = None
search_mode = "hybrid" # keyword-heavy but no structured filter
# Retriever leaf, called by the LangGraph graph after routing
search_results = search_client.search(
search_text=query_keywords,
vector_queries=[VectorizedQuery(
vector=embed(question),
k_nearest_neighbors=50,
fields="description_vector"
)],
filter=odata_filter,
select=["image_path", "description", "ocr_text", "color_names"],
top=10
)
This orchestration layer is where most of the complexity lives, not in the model choice, not in the index configuration. The default hybrid search widget won't parse intent and build filters for you. You write it in application code, you tune it on real queries, and you iterate. Budget more time here than you expect.
On query latency: intent parse, hybrid search, and grounding pass together run 2–5 seconds end-to-end in my implementation. If you skip the grounding pass and surface raw results directly, you land closer to the low end. For most asset-library use cases that's acceptable; if your SLA is tighter, the grounding pass is the first thing to profile.
Where It Breaks
I want to be direct about the failure modes, because this architecture doesn't work equally well for everything.
The color perception gap. This one stung me first. A user searched for "amber product shots." The system extracted "amber" as the color, built a filter for color_names/any(c: c eq 'amber'). Zero results. My indexed color names used coarse HSV buckets: red, orange, yellow, green, blue, purple, pink. Amber falls inside "orange." But the filter was exact string match: "amber" didn't equal "orange," and the system returned nothing.
The root issue: color verbalization happens at ingest time with coarse buckets, and there's no perceptual color distance at query time. You could expand the color vocabulary at ingest, add synonym mappings in the query construction logic, or skip exact color filters and rely on the semantic vector for color-adjacent queries. All of these are trade-offs I haven't fully resolved. The amber/orange problem is small in isolation but represents a broader class: any case where human perception doesn't map cleanly to the coarse vocabulary you chose at indexing time.
Abstract or low-information images. Verbalization works when there's something to verbalize: recognizable objects, readable text, meaningful colors, informative compositions. For abstract graphics, heavily stylized art, or images where the meaning is purely contextual (a cropped background texture, a solid color swatch), the description the model generates is vague. Vague descriptions produce weak embeddings and mediocre search results. The mitigations here are upstream: tag abstract assets manually at upload time, compensate with richer filename and folder metadata, or accept the limitation and surface it in the UI ("search works best on product and scene images"). What you can't fix is asking a language model to describe something that has no language equivalent.
Verbalization-First vs. Embedding-First: How to Choose
If you're deciding between this pattern and CLIP-style image embeddings, here's the honest comparison:
| Criterion | Verbalization-First | Embedding-First (CLIP) |
|---|---|---|
| Existing infrastructure | Yes Works on any text search stack | Needs GPU path or managed image embeddings |
| Query types | Mixed intent: keywords, filters, OCR, dates | Visual similarity — "find images like this one" |
| Structured filters | Yes Color, date, product, region | No Embeddings don't support OData filters |
| Explainability | High — stored text is readable and debuggable | Low — vector matches are opaque |
| Cross-lingual queries | Via embedding model's language coverage | Strong — CLIP's shared space handles this naturally |
| Ingest complexity | One LLM call per image at index time | One embedding call per image, no LLM needed |
These approaches aren't mutually exclusive. Fusing CLIP image vectors with text embedding vectors at index time can outperform either alone, but at the cost of two indexing paths, two infrastructure dependencies, and significantly more complexity to maintain.
For my case (a marketing asset library, a team without GPU infra, users asking mixed-intent questions), verbalization-first was the right call. It runs on the stack we already had, failures are debuggable, and the retrieval logic lives in plain Python code I can reason about.
When I started, we had folders nobody could search, filenames nobody could parse, and executives pulling the wrong slide because "last quarter's Paris shots" meant nothing to a file system. Running vision at ingest, building a proper hybrid index, and writing explicit retrieval logic to bridge language to search. That's what turned ten thousand opaque files into something queryable.
The components aren't novel. The hard part is knowing where the glue goes.
If you've shipped a fix for this class of problem (the system indexed "orange," the user typed "amber," and you found something that held), I'm curious what you chose.