Production ML Without a Data Science Team
How a martech company shipped production ML with no data science team. Silver layer, AutoML, delta inference, and matchback validation to prove it works.


The request came in like most do: straightforward on the surface, complicated once you start building it. A martech company serving over a thousand auto dealer tenants. The business question: which customers are most likely to buy or service next?
A production pipeline driving real ad targeting for real dealers, scoring hundreds of thousands of customers and routing those scores into campaigns.
We had no dedicated data science org. I own the data platform, and my team owns what runs on it. Our job was to build the full loop: data in, model trained, scores served, outcomes measured.
Here's what that build actually looks like, and how we validated it was working before it touched ad spend.
The Before State
Before this pipeline existed, targeting was manual. The analytics team applied filters: customers with vehicles over a certain age, customers who hadn't been in for service in the past twelve months, customers whose leases were expiring.
It worked. Sort of. The problem with manual filters is that they're binary. A vehicle is either "old enough" or it's not. You can stack filters, but you lose the signal that lives in the combination of features.
A customer with an aging vehicle, frequent service history, and an expiring lease is a very different prospect than a customer who just has an aging vehicle. Manual filters can't weigh that combination. A propensity model can.
The Real Work Isn't the Model
Most ML articles skip straight to model selection. That's backwards.
The model is almost the easy part. Training data is where projects die: missing joins, stale records, features computed at the wrong grain. By the time you get to the model, if the data underneath is broken, no amount of tuning saves you.
Start with the foundation.
Our platform runs on a medallion architecture: Bronze (raw ingestion), Silver (cleansed, conformed, joins resolved), Gold (business-ready aggregates). The training layer question matters more than people think.
The Databricks default is Gold. For most analytics, that's correct. But Gold aggregates, and when you aggregate for reporting, you lose the per-customer detail that feature engineering needs.
Bronze is too raw: unjoined records, dirty keys, duplicates. You don't want your training set inheriting those problems.
Silver is the right training layer. It has the complete customer-level picture: sales joined to service records joined to lease terms, all deduped and conformed, but not yet rolled up into summary metrics. That's the grain you need for this problem.
The Features
The features for this model come from the intersection of sales and service history:
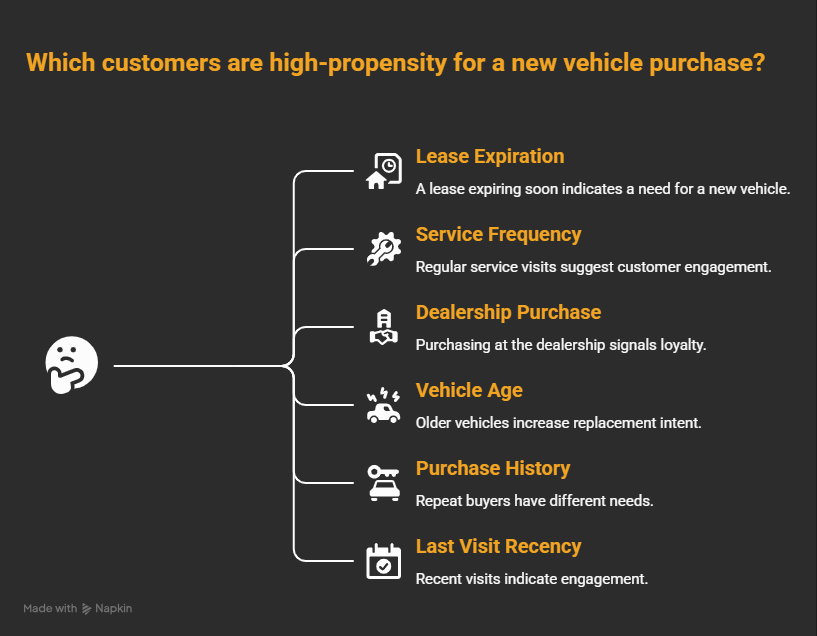
What all of these share: they're slow-moving. Lease terms run for years. Service habits don't flip overnight. A customer who's serviced faithfully for four years doesn't go cold in a month.
This is not an accident. Feature velocity shapes everything downstream, especially how often you need to retrain.
Schema Evolution
When new features become available, we don't retrofit the model mid-cycle. We add them to Silver, update the feature pipeline, and let the model see them at the next scheduled retrain. Schema evolution is handled at the data layer, not by breaking production.
AutoML Picks the Model. You Productionize It.
AutoML evaluates candidates: logistic regression, gradient boosted trees, random forests. It picks the winner on performance metrics. We're not running three-week model bakeoffs or hand-tuning hyperparameters.
Logistic regression won. This wasn't a surprise. The features are direct, the relationships are largely monotonic, and explainability matters to dealers. When a dealer asks why a customer is flagged as high-propensity, we can give a real answer with logistic regression. With a gradient boosted tree, the conversation gets harder.
One domain nuance worth calling out: class imbalance hits the sales model hard. Vehicle purchases are rare events relative to the total customer base, so the class ratio is skewed. Service propensity is a different story: visits are frequent enough that the ratio stays manageable on its own. Treating both models the same way will leave you debugging the wrong problem.
But here's where most ML projects actually die: AutoML produces a notebook. The notebook sits in someone's personal workspace. The model artifact lives in a personal MLflow experiment, not a shared registry. When retraining is due, someone does it manually. Three months later, no one remembers which version produced the current production scores.
We didn't let that happen.
The winning notebook goes to source control. From there: a CI/CD pipeline, a scheduled training job, and the model artifact checked into the MLflow registry.
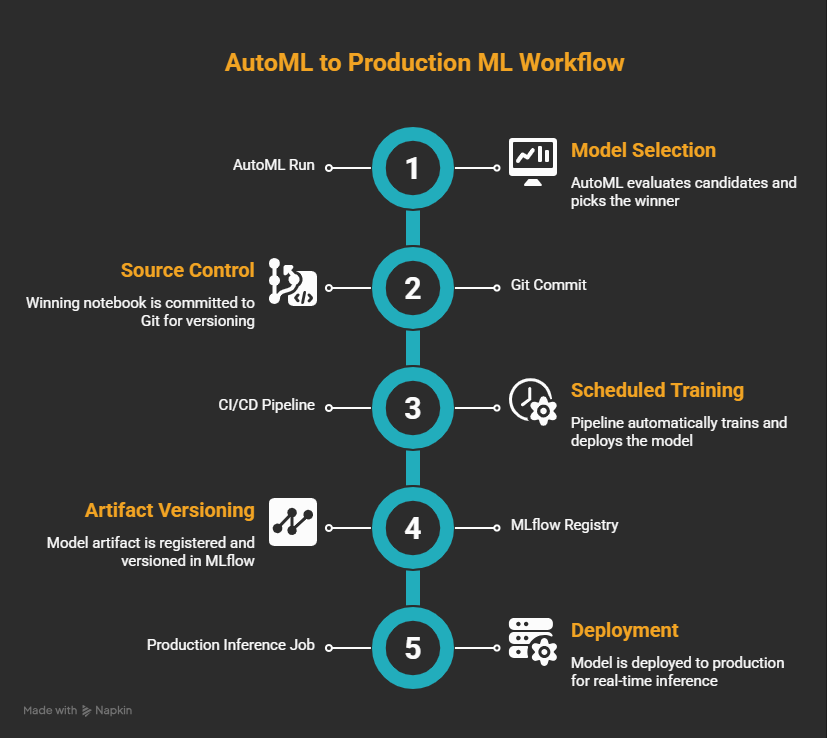
Every training run is logged. Every version is tracked. Rollback is an alias change in the registry, not a frantic search through a personal workspace.
This step is what separates production ML from notebook ML. The model itself matters less than the discipline around it. Without this discipline, you can't run matchback against a known, versioned model. The feedback loop only closes if you know which model you're getting feedback on.
Inference: Batch and Delta
Scoring runs monthly. The full customer population gets scored against the production model, and output lands in the Gold layer. Consumers pull from Gold.
Monthly batch scoring is right for this domain. The features are slow-moving. Daily scoring would compute nearly identical answers with marginally different data and call it freshness.
But there's a gap problem. Between monthly runs, new customers enter the system. If a consumer pulls propensity data on day fifteen and there are customers with no scores, they get incomplete data. In a targeting context, that means campaigns miss people.
We handle this with delta inference. Before each consumer pull, we check for customers missing scores using an anti-join against the existing score table. Any gap gets filled on demand. Consumers always get a complete dataset. This is operational maturity: not glamorous, but the difference between a pipeline that works and a pipeline that mostly works.
The Feedback Loop: Matchback
You can have a clean training layer, a productionized pipeline, well-calibrated scores, and still be completely wrong. Most monitoring setups will catch when input distributions shift (that's what PSI does). What they won't catch is whether the model's predictions are still tracking what customers actually do. Those are different problems.
Matchback closes that gap. Dealers run campaigns targeting high-propensity customers from our scores. After the campaign window closes, we match the responders (customers who actually purchased or came in for service) back against the original scored population. If the high-propensity segment converts at meaningfully higher rates than the low-propensity segment, the model is working.
A word on methodology: matchback measures correlation, not causation. Before releasing, we validated against a pre-campaign window: customers scored but not yet targeted. That gave us baseline signal without targeting contamination. The correlation was strong. We released, and have tracked matchback through live campaigns since.
For domains where ground truth arrives slowly, PSI gives you an earlier tripwire. In automotive, you have something better: actual purchase and service events on a known cadence. Matchback against real outcomes is more meaningful than a distribution similarity score. We didn't add monitoring complexity we didn't need. If we tighten matchback latency and the feedback window still isn't fast enough, PSI becomes the obvious next layer, but that's a problem we'd solve with data pipeline work first.
Retrain Every Six Months
Industry default is to retrain frequently: weekly, monthly, on drift trigger. We retrain every six months.
Your retraining cadence needs to fit your domain. Car buying cycles are measured in years. Lease terms run 24 to 48 months. The features that predict purchase intent are sticky. A model trained in January still describes the same underlying customer behaviors in June. Retraining on a monthly cadence wouldn't improve the model; it would add operational overhead and introduce regression risk.
Off-cycle retraining is on the table for external shocks: a financing rate spike, a supply disruption, a macro event that changes consumer behavior at scale. Absent that, the six-month cadence holds.
The principle: match your retraining cadence to the velocity of your features. Frequent retraining on slow-moving data isn't rigor. It's noise.
What I'd Improve
We shipped a solid system. Here's what I'd tighten with more runway:
A formal feature store with documentation and lineage. Right now, feature definitions live in transformation code. That's fine when one person owns it. It becomes a problem when the team grows or someone needs to audit which features went into a specific training run. A formal feature store with versioned definitions and lineage tracking would fix that.
Tighter matchback feedback latency. Matchback is currently a periodic process tied to campaign windows. Tightening the pipeline so conversion data flows back more continuously would shorten the feedback loop and let us catch model degradation earlier. If that latency problem proves hard to close, PSI becomes an attractive early-warning complement: not as a substitute for ground truth, but as a faster tripwire between campaign windows.
Closing the Loop
Three things made this work. We chose the right training layer (Silver, not Gold). We productionized the notebook instead of leaving it in someone's workspace. And we built a feedback loop that confirmed the scores were tracking reality before they touched ad spend.
We built that chain without a dedicated data science org. The model ran. The matchback held: high-propensity customers were converting at the rates we needed to see before we trusted the scores with real budget. Dealers kept targeting scored lists because the results held up. The ad spend followed.
The improvements above are next iterations: a formal feature store, tighter matchback latency. None of them were prerequisites for shipping. You don't need the perfect MLOps platform to get production ML running. You need the right foundation, a closed loop, and proof before you scale.