Solving AI Sprawl: Using Git Worktrees and ADRs to Govern Parallel Agents
How a five-phase AI-assisted SDLC pipeline (SpecKit, Git worktrees, /done, Claude Poll, /fix-pr) enforces architectural discipline at speed without the AI sprawl.

A year ago, smoke tests on my projects were a luxury: too expensive to justify, too slow to run on every PR, too hard to maintain alongside a fast-moving codebase. Today they're the default output of every feature cycle. Not because I added a QA team. Because I built an AI-orchestrated development workflow that enforces them automatically.
At peak, I'm running five Git worktrees in parallel: five separate feature branches with five separate AI agents implementing, testing, and reviewing code simultaneously. The system is a distributed zero-trust platform: k8s, PostgreSQL, Terraform, Helm, an orchestrator, a database-backed queue, a frontend. For this type of project, a major feature cycle used to take months. Now it takes weeks.
If one person can run this factory, a team of five can run it at five times the throughput. The pipeline doesn't change with headcount; the discipline layer stays constant. But that's the end of the story. Let me start at the beginning: why most teams using AI to ship faster are building a trap for themselves.
The Trap Has a Name: AI Sprawl
I call it AI sprawl.
It's different from technical debt. Technical debt is the shortcuts you take consciously. AI sprawl is what accumulates when you double your PR volume with AI tools and your review process doesn't scale to match. Senior engineers become the bottleneck. PRs pile up. Someone starts rubber-stamping AI-generated diffs, not because they're lazy, but because there are twenty PRs and one reviewer. The "LGTM reflex" kicks in. And the architecture quietly starts to rot.
AI coding tools are, as one engineering director put it, "interns with amnesia." They solve the problem in front of them with remarkable skill. They don't know that the team decided against UUIDs as primary keys in ADR-0001. They see files, not systems.
The answer isn't slowing down AI. It's building a pipeline that enforces what AI can't remember.
In Part 1 of this series, I covered how to govern individual features through invariants, ADRs as fences, and adversarial test suites. This article is the layer above that: how to govern the entire SDLC in parallel, at the speed AI makes possible, without the AI sprawl.
The Pipeline
Five phases. Each one is a gate, not a suggestion.
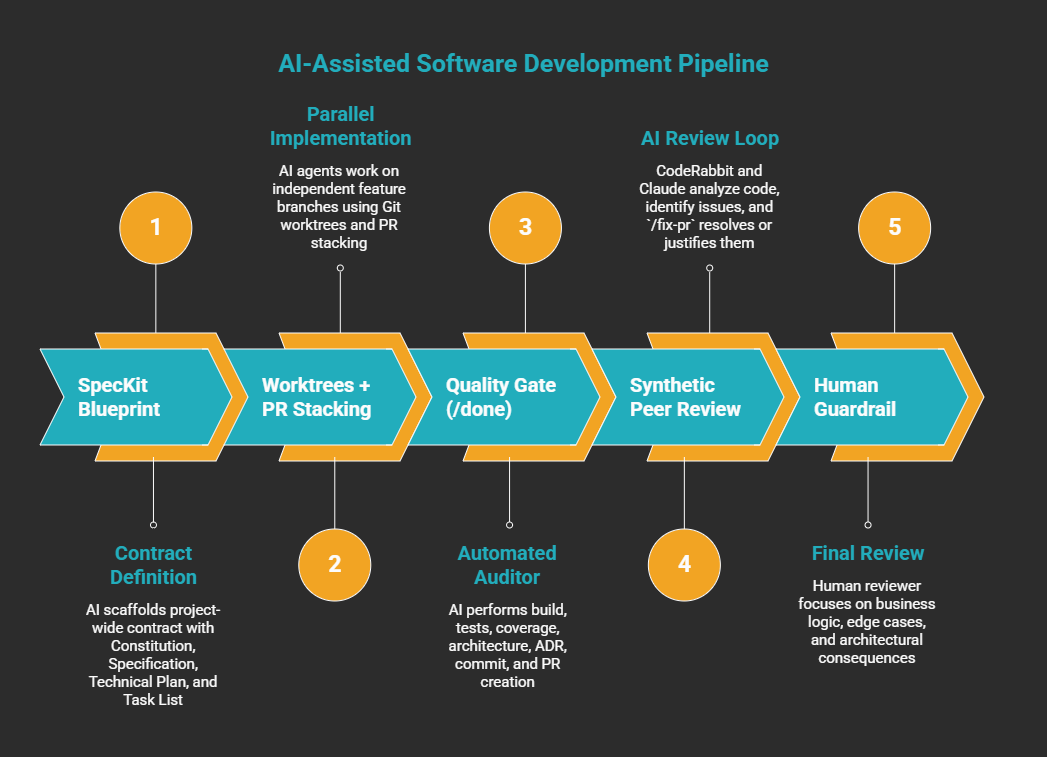
Phase 1: The Blueprint (SpecKit)
Without a spec, you hand the AI a Jira ticket and hope. With SpecKit, you hand it a bounded contract: a Constitution (project-wide non-negotiables), a Specification (goals, user journeys, acceptance criteria), a Technical Plan (architecture and ADRs), and a Task List where SpecKit identifies which tasks can run in parallel.
The lesson I learned the hard way: write the infra spec first. If your infra worktree is the first one to complete, every subsequent worktree iteration can be tested against a real environment from day one. Your deployments, secrets, connectivity, and IAM are validated before any feature code lands. And because it's IaC (Terraform, Helm), if the AI gets something wrong, you fix a file and re-apply. No manual state to untangle. Skip infra and you'll spend your first release debugging missing Workload Identities and Key Vault keys instead of shipping features. I did exactly that.
GitHub SpecKit operationalizes the spec with slash commands: /specify scaffolds the artifact set, /plan breaks it into an ordered task list. The AI agents consume that list; they don't get the full spec as a conversational blob, they get structured, bounded instructions. The spec lives in Git alongside the code. When you change the spec, you're making an architectural decision. That's the point.
Phase 2: Parallel Implementation (Worktrees + PR Stacking)
This is where the factory metaphor earns its name.
Git worktrees let you check out multiple branches simultaneously from the same repository, each with its own working directory, index, and HEAD, all sharing a single .git object store. Practically:
git worktree add ../feature-queue-processor feature/queue-processor
Five of these running, five Claude Code agents working, zero file collisions, zero index corruption, zero context contamination between agents.
At peak I had five worktrees running simultaneously: the infra, the orchestrator, the queue processor, the API layer, and the frontend. Each agent had its bounded spec. Each was building independently.
The second piece is PR Stacking, and most engineers haven't adopted it yet. Traditional workflow: finish a feature, open a PR, wait for review, merge, then start the next. On an AI-assisted team that sequential model is the bottleneck. With stacking, you open a PR, immediately branch off it, and start the next feature. You don't wait for the merge. You have a chain of dependent PRs. When an upstream branch changes, I ask Claude to rebase the dependent branch; Git automatically drops any commits whose changes are already present upstream, keeping the history clean.
Combined, worktrees and stacking transform the SDLC from a linear assembly line into a parallel factory.
To catch infra dependencies before they block a release, I run a dedicated infra skill with read-only kubectl and Azure CLI access that generates a pre-flight dependency report. The /done skill's Human Gate formalizes this further: it scans for every action that requires a human (provisioning, RBAC, secrets configuration, portal access), surfaces the full list, and waits for confirmation before any automated check runs.
Phase 3: The Quality Gate (/done)
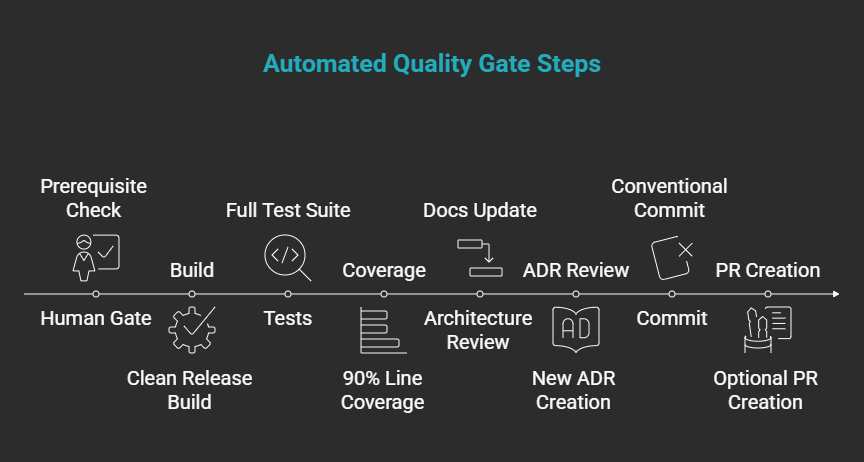
The /done skill is the automated auditor. You trigger it when you believe a feature is complete. It doesn't care what you believe; it checks.
Eight steps, fully autonomous once triggered:
- Human Gate: surfaces all prerequisites requiring human action
- Build: clean release build, zero errors required
- Tests: full test suite, zero failures required
- Coverage: 90% line coverage minimum on Domain + Application layers only (controllers, infra adapters, DI wiring, and generated code are excluded)
- Architecture review: updates
docs/architecture.mdif new containers or external systems were added; C1/C2 level only - ADR review: creates a new ADR if a genuinely new architectural decision was made; ADRs are immutable; deviations create a new ADR referencing the old, never modifying it
- Commit: autonomous conventional commit (
feat:,fix:,refactor:, etc.) - PR creation: optional; asks once, creates via ADO MCP tool
The coverage threshold isn't arbitrary; I scope it to Domain + Application layers only. An API controller doesn't need 90% coverage; the payment processing logic does.
The gate doesn't just report. It blocks. If coverage is below threshold, /done stops, lists the per-module rates, and exits. Fix the code or fix the tests: there's no option to comment and continue.
Phase 4: Synthetic Peer Review (CodeRabbit + Claude Poll + /fix-pr)
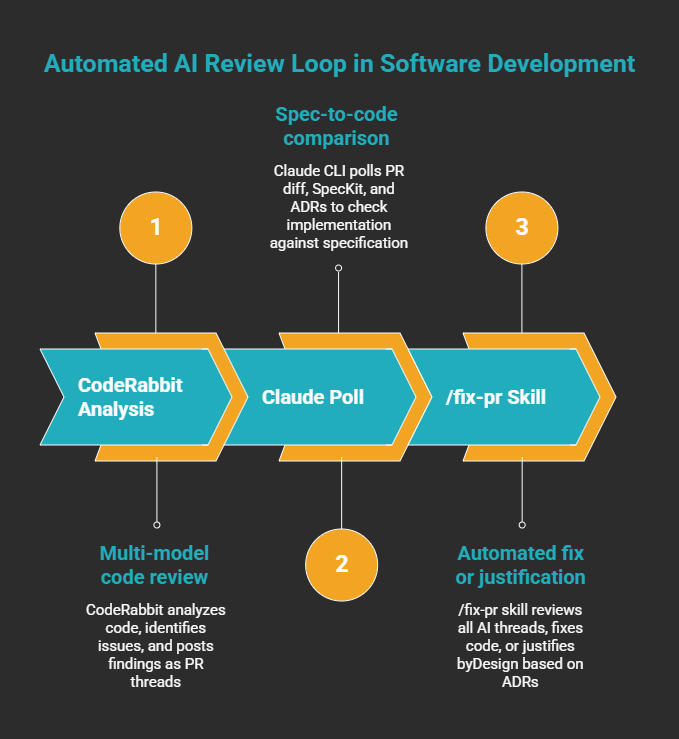
After /done passes, the PR enters an automated review loop before any human sees it.
CodeRabbit runs first: multi-model code analysis, 40+ linter and security scanner integrations, code graph analysis that understands cross-file relationships, and severity-tiered findings posted as PR threads. What makes it useful during human review is the chat interface: @coderabbitai to interrogate a suggestion, @claude to ask Claude a question directly in the PR thread. When I'm reviewing, I'm not switching contexts — every AI I need is reachable inline.
The Claude Poll runs on a cron job (Claude CLI, scheduled). It reads the PR diff, loads the originating SpecKit spec, and pulls all relevant ADRs. It posts its findings as PR threads. But its question is different: not "is this good code?" but "does this implementation match what was specified?"
A third Claude CLI cron job closes the loop by running /fix-pr, a skill that polls all active PR threads (from CodeRabbit and from the Claude Poll) and works through every one. For each thread the skill loads only the context that comment requires: the affected file, the relevant ADR, or the spec section in dispute. Then it decides: fix or justify.
If the fix is clear, it commits it, pushes, and marks the thread Fixed. If the comment conflicts with a spec clause or an ADR decision, it replies with the exact clause and marks the thread ByDesign. Nothing sits open without a response.
AI defending correct code against other AI suggestions, using your own ADRs as the authority.
Say CodeRabbit suggests switching to UUIDs for primary keys. /fix-pr reads that thread, loads ADR-0001, sees that integer IDs are the established standard, and closes the thread with a ByDesign response, explaining why the existing code is correct and linking directly to the ADR. The code stays unchanged. The suggestion is dismissed with a documented reason, not just ignored.
If the suggestion is legitimate and the ADR genuinely needs revisiting, that's a separate conversation. ADRs aren't changed by one person in a PR comment; the team reviews them together, agrees on the new direction, and a new ADR is written before the code changes. The pipeline enforces that sequence.
Phase 5: The Human Guardrail
By the time a PR reaches a human reviewer, it has passed a build and test gate, a coverage gate, a code quality review, and a spec compliance review. The pipeline checked coverage. The pipeline enforced naming conventions. The Claude Poll caught architectural violations.
The human reviewer focuses on what automation can't assess: business logic correctness, edge cases no spec anticipated, and architectural decisions with consequences the pipeline couldn't predict. The cognitive load is dramatically lower. The review is faster and, paradoxically, more thorough, because the reviewer is looking at the right things.
Does This Work on a Team?
Yes. And if you're running Agile, the mapping is already there. Your features contain the spec: user stories become the acceptance criteria in the SpecKit Specification, and the architect adds the Constitution and Technical Plan (ADRs) on top. The feature boundary and the spec boundary are the same thing. Each engineer picks up a feature, gets a worktree, and works against that bounded contract.
Ownership scales cleanly: the architect owns the SpecKit Constitution and Technical Plan. Engineers own their feature specs and worktrees. When the Claude Poll surfaces a finding that conflicts across features (say, two engineers made different assumptions about a shared service boundary), it escalates to the architect. This works because the Claude Poll's context includes the full shared ADR set: two engineers violating the same ADR in separate PRs both get flagged independently. The ADR is the cross-PR consistency layer. One decision, recorded as a new ADR, resolves it for the whole team. A three-person team each running three worktrees means ten features in parallel. The discipline layer stays constant.
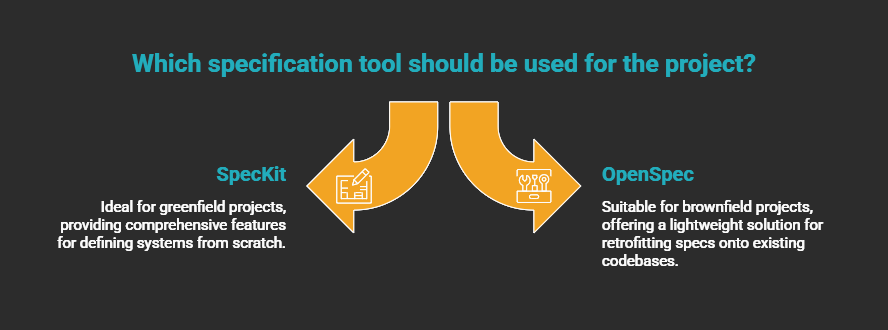
The pipeline works on both greenfield and brownfield: pick the right spec tool for the context. SpecKit shines when you're defining a system from scratch. On brownfield codebases, where you're retrofitting specs onto decisions made years ago, I prefer OpenSpec: it's more lightweight and doesn't assume you're starting from a blank slate. Either way, start with the feature area that changes most frequently and expand from there.
What the Pipeline Actually Changes
Feature cycles dropped from months to weeks. Smoke tests went from a luxury I couldn't justify to a default output. Those are the numbers. But the change that matters more isn't in the velocity metrics.
It's that I can hand this codebase to another architect and they can understand every decision. The ADRs are current. The architecture diagrams reflect what's actually deployed. The specs are versioned in Git alongside the code they describe. None of that came from AI. It came from building a pipeline that refuses to let those artifacts fall behind.
The architect's job in this model is three things: designing the pipeline, writing the SpecKit constitutions that define the boundaries AI agents work within, and reviewing the escalations the pipeline couldn't resolve on its own. Not reviewing every PR for correctness. Not chasing coverage gaps. Not catching naming violations after the fact.
The pipeline handles the mechanical discipline. The architect handles the decisions that require judgment. That's the separation this workflow is built around.