Architecture Artifacts in Order: The Missing Handoff Between Discovery, Design, and Delivery
How to chain event storming, ADRs, C4, and arc42 into a repeatable pipeline where each artifact feeds the next. A practitioner walkthrough with diagrams.

Event storming has a whole book. arc42 has a website with 12 numbered sections. ADRs have Michael Nygard's original 2011 post and a hundred adaptations of it. C4 has Simon Brown teaching it to thousands of people across 40 countries. Not one of them tells you what output to hand to the next practice.
I've used all of them. On different projects, in whatever order felt right. The event storming insights stayed in a Miro board. The ADRs sat in a docs folder that didn't reference the bounded contexts that motivated them. The C4 diagram referenced components the event storming had grouped differently. I never found a pipeline that connected them into something I could repeat.
This article walks through the pipeline I now run for any system with real scope. I'll use a fictional example throughout: an ERP-style system sitting between a CRM and a legacy operations database. It pulls deal data from the CRM, manages campaign lifecycles, and propagates changes back to the ops DB. Common enough shape that most architects have touched something like it.
What changed was not the individual practices. It was designing the handoffs between them. Requirements feed event storming. Event storming feeds bounded contexts and aggregates. Those feed RFCs, ADRs, APIs, C4 diagrams, deployment intent, and backlog items. Each artifact has an input, an output, and a reason to exist.
I run this workflow with AI assistance, but the tool isn't the point. The point is that every step has explicit inputs, explicit outputs, and a review gate before anything gets written. Part 2 covers the execution model.
The practices you already know, and the glue you don't have
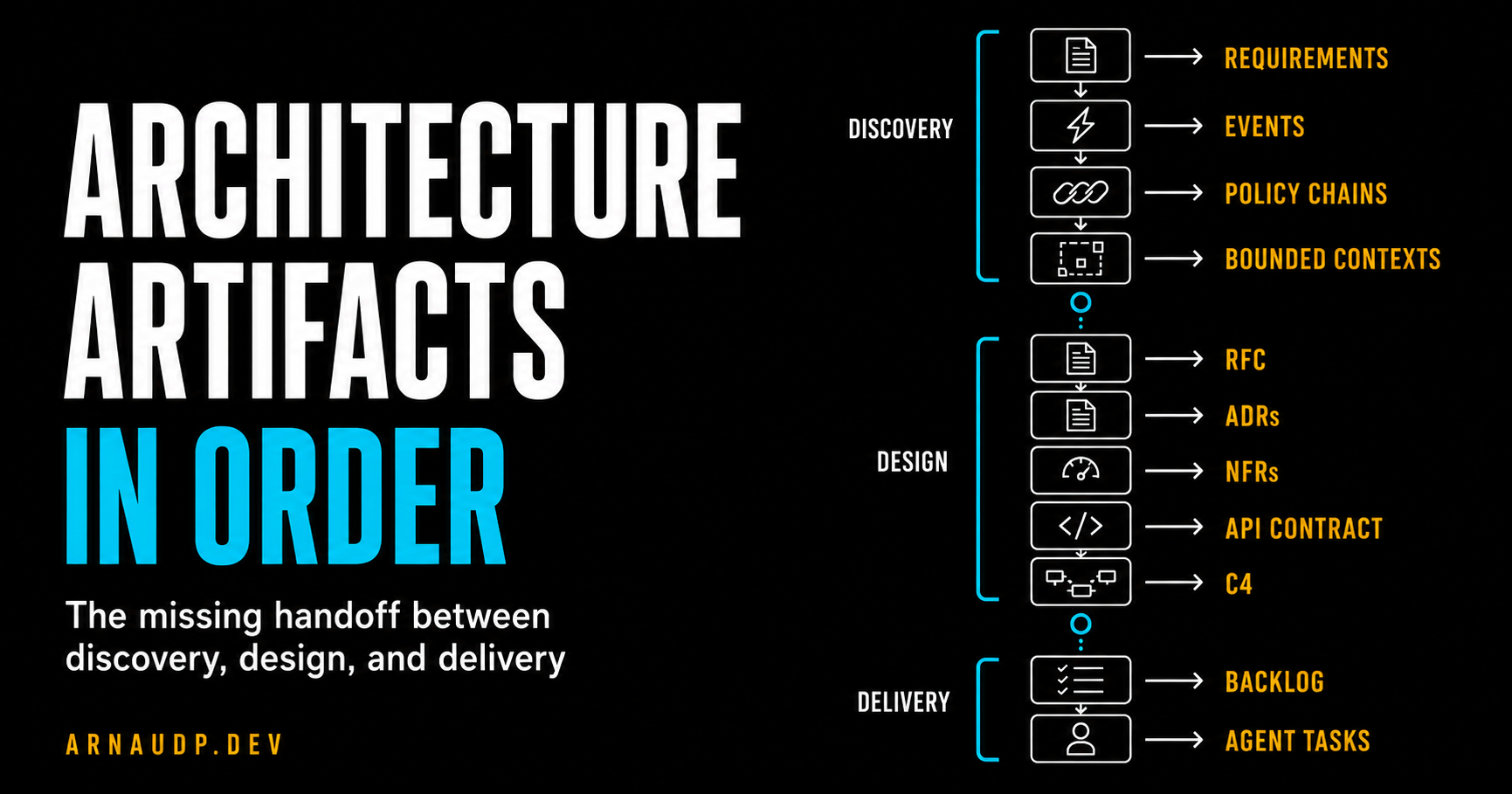
Here's what the chain looks like for a Large-tier project. Each step produces output the next step requires: you can't run policy chains without domain events, and you can't draw a C4 container diagram before you know your bounded contexts.
Discovery:
Requirements → Domain Events → Timeline → Policy Chains → Aggregates → Bounded Contexts → Read Models
Design:
RFC → ADRs → NFRs → API Contract → Risk Register → C4 Context → C4 Containers → Domain Model → Crosscutting → Deployment → Data Flow
Delivery:
Stakeholder Pack → Confluence → Backlog → Agent Tasks
I use three tiers to control how much of that chain runs on any given project.
Small gets me an ADR and an API contract. Medium adds event storming, an RFC, NFRs, and risks. Large adds the full C4 stack, domain model, crosscutting concepts, deployment intent, and data flow.
Tier selection is about scope, not importance. A config change doesn't need a bounded context diagram.
For this fictional system, sitting between a CRM and a legacy operations database with multiple integration points, the scope is Large.
Discovery: from requirements to bounded contexts
Requirements gathering
I start with a conversation. No wireframes, no database schemas, nothing about how. Just: what does this system have to do? Every obligation gets a REQ prefix and a number.
For a system like this you'll end up with requirements across multiple sections: campaign lifecycle, CRM integration, change management, data migration. The sections emerge from the conversation, not from a template.
Here's a sample from this system:
REQ-C01 A campaign must exist in one of three states: Active, Completed, or Cancelled.
REQ-CRM02 The system must automatically detect and import new CRM deals that meet
campaign criteria without user action.
REQ-CHG04 When a mail quantity override occurs and the new value differs from the CRM
sold baseline, the system must automatically create a change request task on the
corresponding CRM deal.
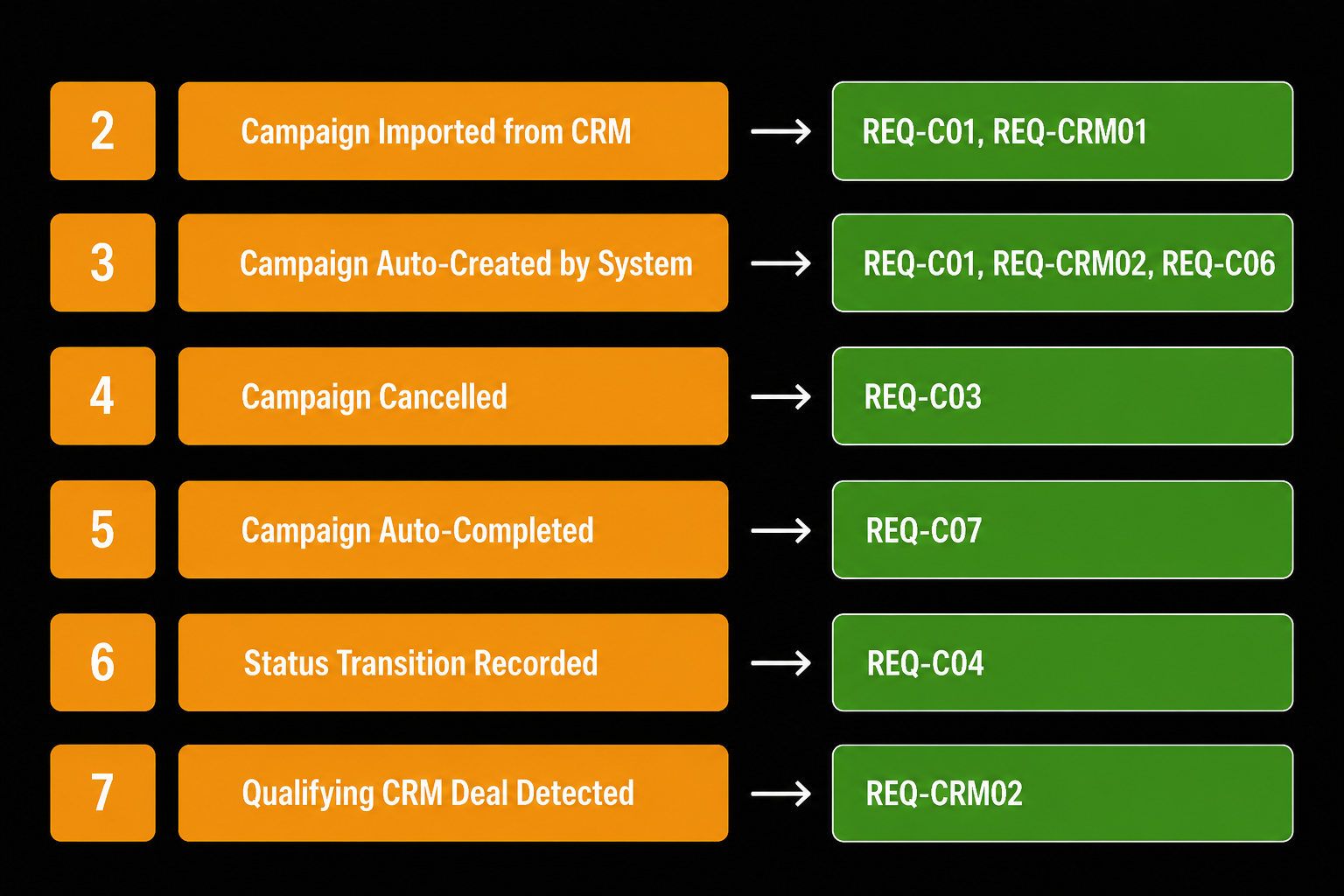
The REQ prefix is what I use for traceability. Every domain event, every ADR, every API endpoint, and every backlog item points back to one or more REQ codes. I can't run event storming on "the system should handle campaigns." I can run it on the specific numbered requirements for that domain.
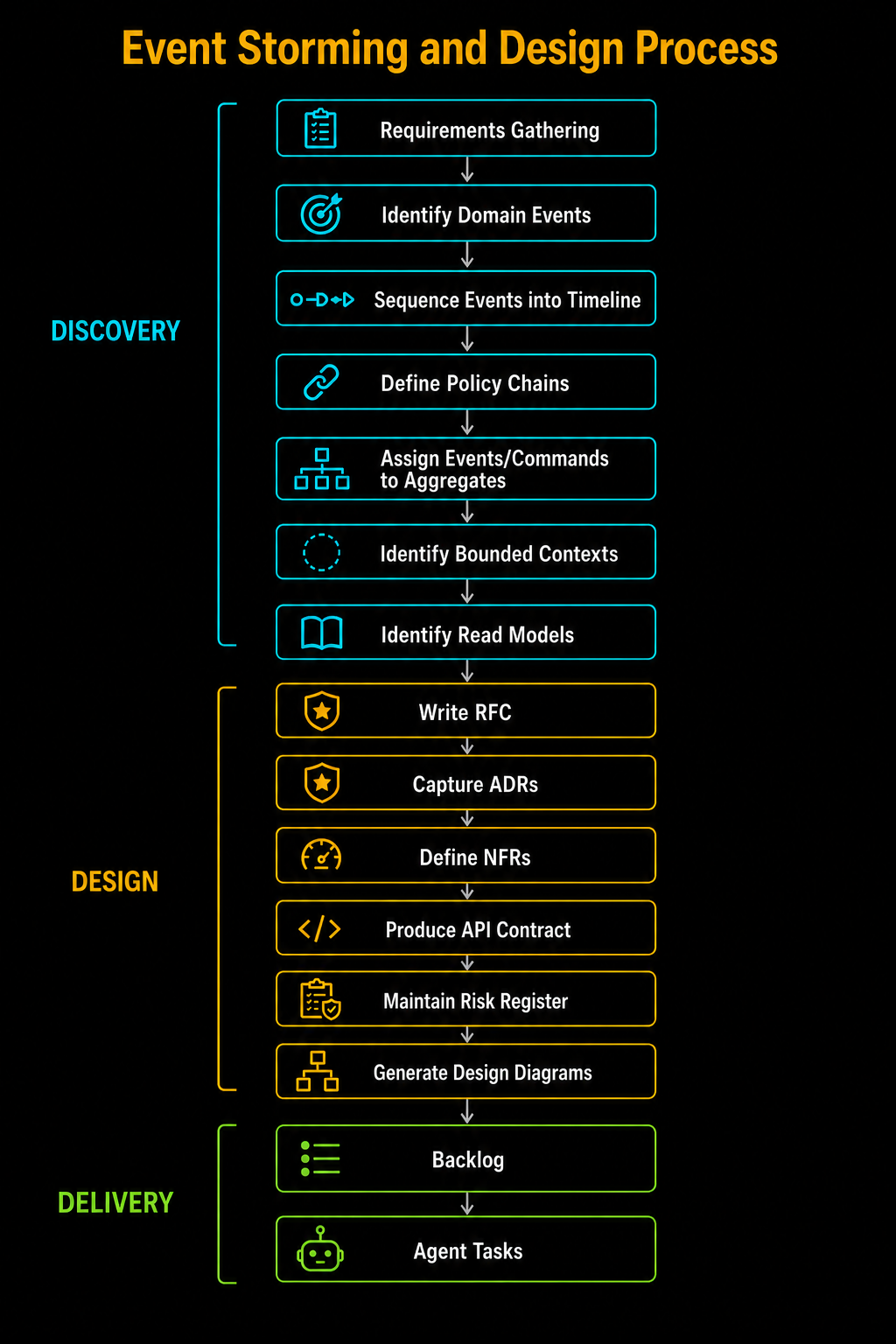
Domain events
Domain events are past-tense business facts, not system actions and not technical operations. When I first did this I kept writing things like "User creates campaign." That's an instruction. An event is what already happened: "Campaign Auto-Created." Past tense. Done deal.
Each one points to one or more REQ codes that required it to exist. If I can't trace an event back to a requirement, it doesn't belong in the model.
A system like this generates dozens of domain events. Here's a section of the table:
Notice event #1 is missing. I reserved it for a deferred event that didn't make the final cut. I don't reuse numbers. The gaps are intentional.
Timeline
With that many events I need to know what order they happen in and who causes each one. I sequence them into a timeline and tag every event with its actor: system scheduler, CRM webhook, internal API call. If two events can't be ordered relative to each other, that's a gap to resolve before moving on. The timeline doesn't give me a publishable artifact on its own, but if I start policy chains with events in the wrong order, I get chains that don't reflect reality.
Policy chains
Policy chains are the core of event storming for me. The fundamental unit is simple: a Command hits an Aggregate, the Aggregate produces an Event.
What connects them into chains is the policy: an optional automation rule that materializes "whenever event X occurs, trigger command Y." Not every event needs one. If the connection is direct and unconditional, you can have Event → Command → Event with no policy in between. The policy sticky is how you make the conditional or reactive logic explicit, not a structural requirement for every step.
In a system with heavy CRM integration, most of the interesting behavior is automated reactions: a deal arrives, conditions are evaluated, commands fire. That's where policies earn their place.
I treat these rules as non-negotiable:
- A policy is optional: use one only when you need to materialize a conditional or automated reaction
- When a policy is present, it connects exactly one triggering event to exactly one command
- No two events in a row without a command between them
- No two commands in a row without an event between them
- Branching happens in parallel from the triggering event, not sequentially from the last event
- Conditional paths use dashed arrows (fires only sometimes); unconditional paths use solid arrows
Here's Chain 1, Campaign Birth (Auto Path):
Traditional event storming uses a physical wall or a Miro board with color-coded stickies. I produce Mermaid diagrams instead. The color conventions map directly to the sticky-note taxonomy:

Node labels follow the pattern: actors are roles or systems, commands are imperative phrases, events are past-tense facts with an ID number, policies are conditional "when X" triggers. Solid arrows are unconditional; dashed arrows are prerequisites that fire only sometimes.
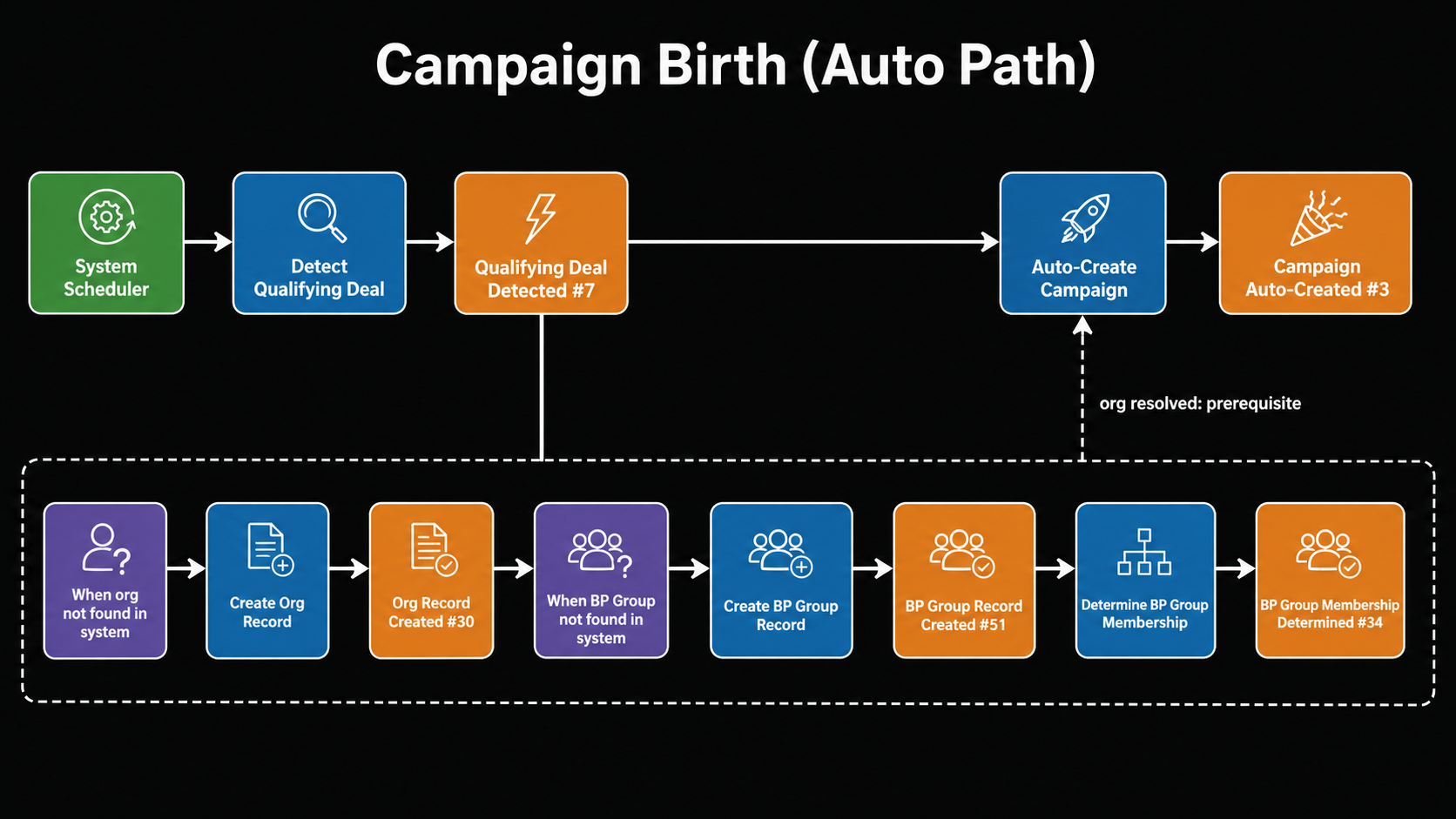
The dashed arrow from E34 to CMD_CREATE is the prerequisite pattern: auto-campaign creation can't complete until org resolution has run. That constraint wasn't in the requirements text. I found it through event storming.
The output is version-controlled and diffable. I can diff two versions of a policy chain the same way I diff code, and it feeds directly into the design phase without a translation step.
Here's what those rules actually catch.
One of my early chain drafts had two domain events in sequence with no command between them. The rules say that's illegal: you can't have an event cause another event directly. Tracing the gap, I found a missing command, which meant a missing aggregate operation.
That aggregate operation required its own decision: how does the system map CRM template values to its own template configuration? That became an ADR on CRM template mapping strategy. The gap in the diagram surfaced a decision I would have buried in the code.
Aggregates
After the chains are done, I go back through every command and every event and assign each one to an aggregate. An aggregate owns a piece of state: commands come in, events come out, the state lives inside. For this system that gives me Campaign, Organization, BP Group, TemplateMapping, CampaignTypeMapping, and a few others.
Each aggregate ends up with a command-card subgraph: every command it handles, every event it produces. I use that directly as input to bounded context grouping.
Bounded contexts
This is where the DDD structure becomes visible to me. A bounded context is where words have fixed meanings in the codebase. Step outside it and "campaign" might mean something different to another part of the system.
This system has three bounded contexts:
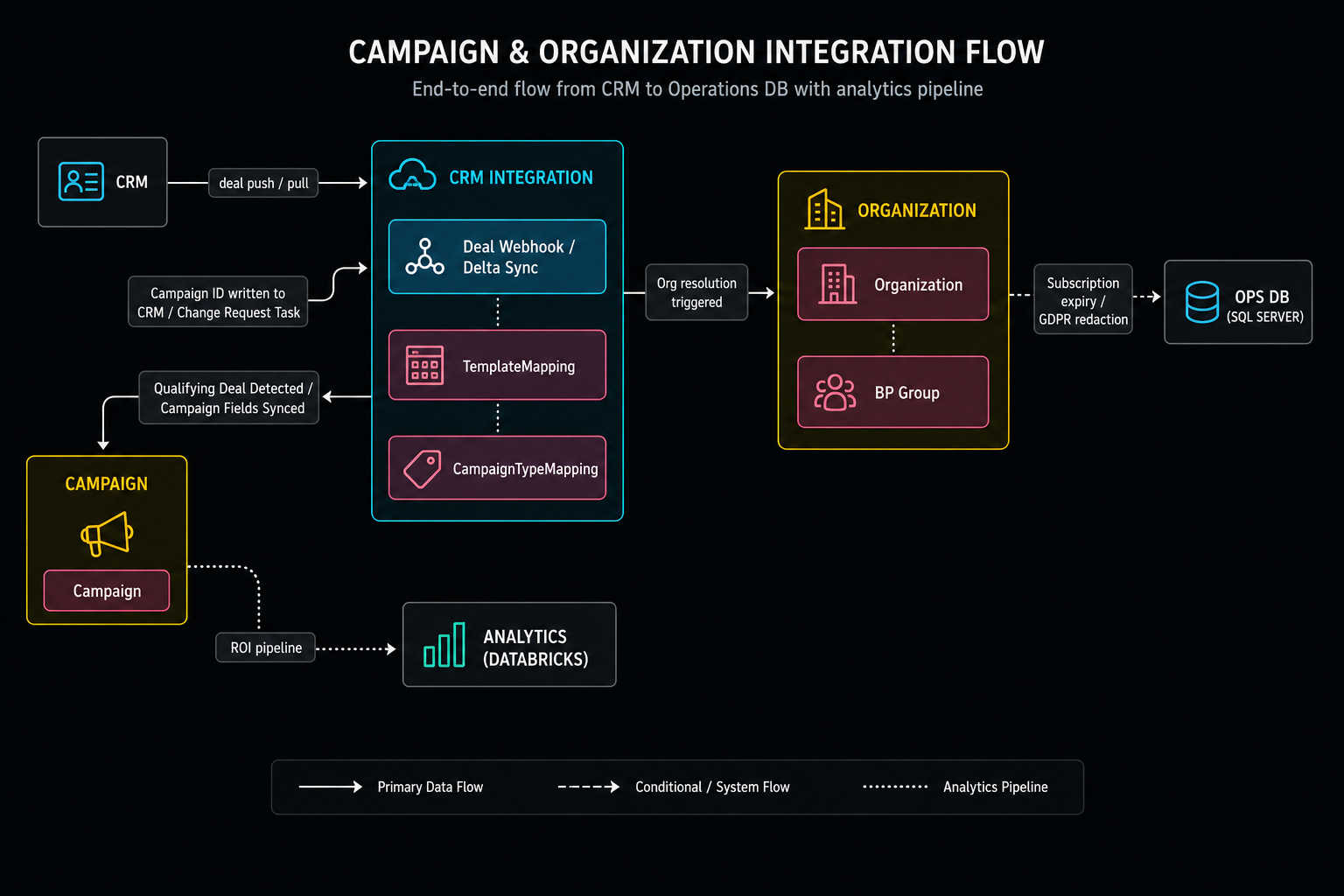
Three contexts: CRM Integration (inbound/outbound), Campaign (the core), Organization (org and BP Group). This diagram becomes the input to the RFC, the C4 containers, the domain model, and the deployment intent. If I skip event storming and go straight to the C4 container diagram, I'm guessing at the context boundaries. I've done it. The diagram ends up wrong.
Read models
Read models are the query surfaces that cross aggregate boundaries: views or projections that need data from more than one aggregate. In classic event storming these are the green stickies. For this system I identified the campaign dashboard view (Campaign plus Organization data), the audit log view, and reporting aggregates. They don't produce events; they're my signal for where CQRS split points belong.
Requirements as a living document
Requirements don't stay fixed through discovery. I find gaps every time I run a step.
The timeline catches ordering ambiguities I didn't know existed. Policy chains catch missing commands, which point to missing aggregate operations, which sometimes surface a decision nobody had made explicit yet. That's what produced an ADR on CRM template mapping strategy: a gap in a chain diagram became a question, the question became a decision, the decision became a record.
A set of migration requirements didn't exist when I started. They came in after the initial 22 steps when scope expanded to cover legacy data migration. That addition had a defined propagation path: a drift check ran, issues were found and resolved, risks were added, chains were extended, the domain model got new entries.
That's why the REQ-prefix matters. When a requirement changes, I can trace exactly which downstream artifacts reference it. The AI carries that traceability forward because it has the complete context of every prior step.
Design: from RFC to data flow
By this point I know every bounded context, every aggregate, and every external system. The design phase isn't about discovering topology; it's about recording decisions I've already made.
RFC
An RFC is a one-page proposal I write before committing to the full design. The audience is the team and stakeholders: it gives them something short enough to actually read and react to before I spend time on detailed architecture docs. It covers the system context, the proposed approach, and an explicit not-in-scope list. The system context diagram is a PlantUML C4 L1. If there's disagreement about scope or approach, I want it here, not after a dozen ADRs have been written.
ADRs
Each ADR captures one decision: Title, Status, Context (what forced it), Decision (what I chose and why), and Consequences (what gets better, what gets harder). I number them sequentially, and when a decision changes, I supersede the old ADR rather than delete it.
NFRs
Latency targets, throughput, availability SLOs, compliance requirements: the things that don't show up in user stories but bite you in production. I feed them into the crosscutting concepts section and the risk register.
API contract
I produce two formats. A markdown table for humans: endpoint, method, request shape, response shape, auth. An OpenAPI 3.1 YAML for machines.
My convention (following CQRS separation): command endpoints return {id} only for client correlation, query endpoints return full resources. I produce the contract after the aggregates are locked, so every endpoint maps to a real aggregate operation.
Risk register
The risk register is for the team and stakeholders: it makes the things most likely to hurt the project visible and owned. Each entry gets a likelihood, an impact rating, and a mitigation. It's not a compliance artifact; it's a conversation starter. New risks come in whenever scope expands, not just at the start, so the register stays live throughout the project.
C4, domain model, crosscutting, deployment, data flow
C4 System Context, C4 Containers, Domain Model, Crosscutting Concepts, Deployment Intent, Data Flow. I run these six in a single session.
Every bounded context, every aggregate, every external system, every ADR, and every NFR is already settled by this point. That's what makes this different from drawing a C4 diagram at the start of a project: I'm not guessing. The diagrams are a rendering of decisions that are already made.
They're only as good as the event storming that fed them.
What's in the folder when you're done
Here's the docs/ tree after all 22 steps:
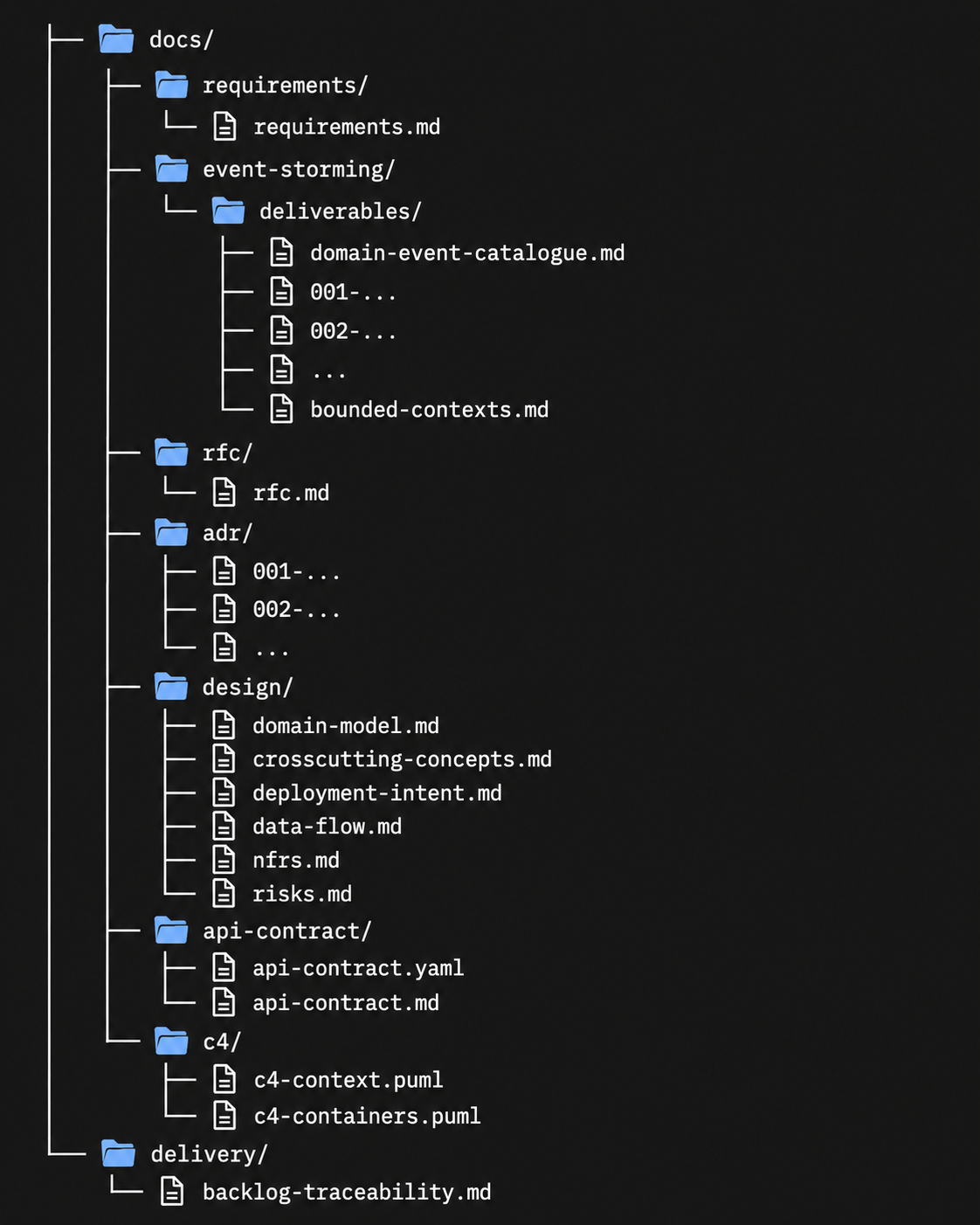
Everything in that tree connects to a REQ code. I can follow the chain from any artifact back to the requirement that created it.
When a requirement changes, I know exactly which artifacts to update. Part 3 covers the drift check that catches the ones I missed.
The handoff is the point
I didn't invent event storming. I didn't design arc42 or the C4 model or the ADR format. I've been using pieces of this for years on different projects. The individual practices were never the problem.
I use the tier system so it doesn't have to be all-or-nothing. A config change gets an ADR and a drift check. An internal service gets Medium-tier: event storming, RFC, NFRs, risks. The full Large-tier run is for something like this: CRM integration, legacy database propagation, multiple bounded contexts.
Part 2 covers how each step actually runs: the Claude Code slash commands, the hard gate pattern that stops execution until I've reviewed the output, and what "peer architect, not assistant" looks like in practice.
This is Part 1 of a 3-part series. Part 2: Turning Architecture Into a Prompt Pipeline.