Claude Code Slash Commands as an Interaction Vocabulary
Claude Code custom slash commands as a vocabulary: named modes with output contracts make agent output reproducible.


Monday morning, I ask Claude Code to review a plan. I get this:
| Conflicts | Gaps | Verdict |
|------------------|------------------|-------------------|
| Auth ADR breach | No NFR for p99 | major-conflicts |
Friday night, same plan, slightly different phrasing because I'm tired. I get this:
The plan looks mostly fine, though I noticed the auth section
doesn't fully align with the ADR you wrote last month, and the
NFR section is silent on latency targets...
Two runs. Two shapes. Nothing wrong with either of them in isolation. But I can't build a workflow on top of "whatever Claude felt like producing today." I can't write a script that reads the verdict line if half the time there isn't one. I can't tell a teammate "run /review-plan and paste the table" if the table is optional.
This is the problem I built my slash-command skills to solve. The fix isn't a better prompt. The fix is a vocabulary.
Here's what /review-plan returns now, every time, regardless of how I phrase the surrounding sentence:
### Overall verdict: simplify-first (worst-wins across reviewers)
### Top blocking issues
1. ...
2. ...
3. ...
### Quick wins (<15 min)
- ...
- ...
### Per-reviewer verdicts
| Reviewer | Verdict | One-line summary |
|---------------------|-----------------------|------------------|
| Conventions Auditor | minor-conflicts | ... |
| Pragmatic Engineer | simplify-first | ... |
| Delivery Lead | needs-task-breakdown | ... |
### Recommended next step
[one actionable sentence]
<details>Full reviewer outputs below for drill-down.</details>
That shape is the contract. The skill cannot return anything else, because the body refuses to. Each reviewer has its own verdict vocabulary (the Conventions Auditor speaks aligned / minor-conflicts / major-conflicts, the Pragmatic Engineer speaks ship-it / simplify-first / rethink, the Delivery Lead speaks ready-to-execute / needs-task-breakdown / not-actionable), and the overall verdict picks the worst of the three so the user can't ship past the most pessimistic lens.
A slash command isn't a saved prompt. It's a named mode with an output contract.
The shift: prompts to vocabulary
Most articles on Claude Code skills treat them as a productivity grab bag: ten must-have skills, ten ways to save time. That framing misses what's actually happening.
A slash command isn't a saved prompt. It's a named mode with an output contract. When I type /review-plan, I'm not asking Claude to do something; I'm invoking a procedure I wrote, with hard gates Claude can't skip and a result shape I can rely on. The skill name is the verb. The body is the contract.
Anthropic's own engineering blog put this nicely: the shift is from prompt engineering to context engineering. The question stops being "how do I phrase this?" and starts being "what configuration of context produces the behavior I want, every time?" Once that lands, the answer is a closed set of named modes you invoke by reflex. A vocabulary.
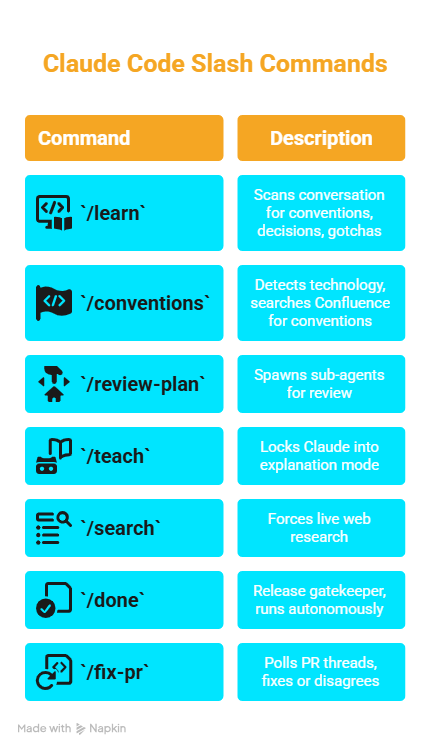
I have more than this in my own setup, but seven of them carry the design ideas I want to show. I'll walk through these, grouped by what they're for:
- Context-loading:
/learn,/conventions - Reasoning:
/review-plan,/teach,/search - Execution:
/done,/fix-pr
A healthy vocabulary stays narrow on purpose so each skill has a clear, recognizable purpose and doesn't dissolve into a grab bag. The mechanical cost is smaller than you'd guess. Claude Code uses progressive disclosure: at session start it loads only the YAML frontmatter from each skill, roughly 60 to 150 tokens for name plus description. Bodies load on activation. The skill listing has a budget of around 1% of the model's context window (configurable via SLASH_COMMAND_TOOL_CHAR_BUDGET), and when you exceed it the descriptions for your least-invoked skills get shortened first, so the ones you actually use keep their full text. The hard per-skill cap is 1,536 characters on the description itself, not a budget shared across all of them.
What that means in practice: you can run dozens of skills, and I do. The cost of an extra skill is roughly 100 tokens at session start. The real reason to stay disciplined isn't tokens, it's signal quality. Every additional description is another candidate Claude has to match against, and a vague twenty-skill vocabulary will fire the wrong skill more often than a sharp twelve-skill one. Run /doctor if you want to see whether your listing is overflowing the budget; otherwise, design for clarity and let the headcount be what it is.
The mechanics: SKILL.md, hard gates, output contracts
Every skill lives in ~/.claude/skills/<name>/SKILL.md. The file looks like this:
---
name: review-plan
description: Review an implementation plan from three angles in parallel (conventions alignment, code-grounded sanity + KISS, task/deliverable completeness). Use when the user says "review the plan", "/review-plan", or wants a second opinion before execution.
version: 1.0.0
triggers:
- /review-plan
---
# /review-plan: Three-Lens Plan Review
Launch three sub-agents in parallel, each with a distinct persona, then
synthesize their findings into a single report with a clear verdict.
Three things in that frontmatter do all the work.
The description is what Claude reads when deciding whether to fire the skill. It can be up to 1,536 characters; Anthropic's authoring guide gives the formula for what goes inside that budget: what it does + when to use it + key capabilities. If you write "a helpful skill for code review," the LLM has nothing to match against and your skill never triggers. If you write "Reviews an implementation plan from three angles in parallel: conventions alignment, KISS sanity, task completeness," Claude knows exactly when to reach for it.
The triggers list pins explicit invocation. /review-plan always activates the skill, regardless of how I phrase the rest of the sentence.
The body is the procedure. Not a description of what the skill does. A procedure: numbered steps, hard gates, output contracts.
That last point is the one most people miss. A skill that works reads like a runbook, not a prompt. Here's the opening of /learn:
## Step 2. HARD GATE: Ask before writing
NEVER write to any file before the user answers this question.
Call AskUserQuestion with one question per learning item that has an
ambiguous destination, OR one combined question if all items belong
together.
That's not a suggestion. That's a refusal pattern. The skill cannot proceed past Step 2 until the user has answered a structured multiple-choice question. The output contract isn't enforced by hoping Claude reads carefully. It's enforced by the gate being procedurally impossible to skip without violating the skill's stated rules.
Negative space does most of the work. Telling Claude what NOT to do produces more reproducible behavior than any amount of positive prompting.
Telling Claude what NOT to do (don't write speculatively, don't search after answering, don't leave any thread without a reply, don't proceed without confirming the human gate) produces more reproducible behavior than any amount of positive prompting.
The seven skills, by what they lock in
Context-loading: /learn and /conventions
/learn runs at end of session. It scans the conversation for conventions established, decisions made, gotchas found. Then it calls AskUserQuestion for each item: save it where? Existing skill, project CLAUDE.md, user CLAUDE.md, memory, Confluence, skip. Only after I answer does it write. No more "Claude, please update my CLAUDE.md with what we just figured out" and hoping it remembers the right things.
/conventions is the inverse. Given a path to a code artifact, it detects the technology (C#, Terraform, TypeScript, Databricks), searches our Confluence Engineering Standards space by CQL for an existing conventions page, and compares the artifact against it. If a page exists, it surfaces conflicts and additions for me to resolve. If none exists, it extracts observed conventions from the code and offers to create one. Never updates Confluence without explicit approval.
Both skills treat context loading as a first-class operation. Not a side effect of a long prompt.
Reasoning: /review-plan, /teach, /search
/review-plan is where the Task tool earns its name. The skill spawns three sub-agents in parallel: a Conventions Auditor that reads our Confluence standards and project ADRs, a Pragmatic Engineer that does a code-grounded KISS review of the actual repo, and a Delivery Lead that asks whether the task list is shippable (Definition of Done per task, test inventory, TDD ordering, dependency graph). Each sub-agent gets an isolated context window. None of them see each other's output. Then the parent synthesizes their three structured verdicts into a single report with a worst-wins rule on the overall verdict, so the most pessimistic lens never gets quietly outvoted.
Sub-agents in Claude Code can't spawn their own sub-agents (one-level hierarchy), and they don't stream thinking output; they return a final report. That's exactly the output-contract shape you want for a parallel-lens review. Three independent voices, three structured returns, one synthesis.
The skill also has modes: /review-plan <N> runs up to N rounds of safe auto-fix after each review (convention conflicts, missing test inventory, TDD reordering, anything mechanical), and /review-plan task-drift skips design review entirely and runs just the mechanical task-list validator. The modes are different output contracts, selected by the same verb.
/teach is the simplest of the seven. It locks Claude into explanation mode for one response. Define terms on first use. Show the why, not just the what. Assume zero prior knowledge of the topic. No hedging, no padding. The body of /teach is barely thirty lines, and most of those lines are rules about what not to do.
/search forces live web research. Search before answering, not after. Rank sources: official docs > RFC > changelogs > Stack Overflow accepted > blog posts. Cite inline, not at the bottom. Surface contradictions with training data explicitly ("My training suggested X, but the current docs show Y"). The output contract is: every factual claim in the response has a URL next to it.
/teach and /search compose. I can type /search /teach how does JWT validation actually work? and get a researched, cited explanation in teacher mode. The order matters: /search scopes the research, /teach shapes the prose. Composition is a first-class design concern, not an accident.
Execution: /done and /fix-pr
/done is my release gatekeeper. One upfront AskUserQuestion block (coverage threshold? deep docs analysis? security scan? create PR? target branch?), then it runs autonomously: build, security scan, tests, coverage, architecture review against ADRs, docs accuracy check, commit, PR.
There's one piece of /done I want to call out: the human gate. Before anything else runs, the skill scans the session for actions a human must perform manually: provisioning infrastructure, configuring secrets, granting role assignments, approving a PR. If any of those exist, the skill stops and prints them with a "Reply 'done' when complete" prompt. It doesn't try to work around the gate. It doesn't pretend the work is finished. It refuses to proceed.
That refusal pattern shows up everywhere in my skills. It's the thing that makes the output contract real.
/fix-pr polls active PR review threads (CodeRabbit and human), and for each one it either fixes the code and marks the thread Fixed, or replies with a justified disagreement citing the spec, ADR, or official docs and marks the thread WontFix or ByDesign. Every thread gets a response. No thread is silently ignored.
It also lazy-loads context. The skill has a lookup table of trigger phrases to reference documents: comment mentions architecture, read the C2 section of docs/architecture.md; comment mentions a pattern decision, scan ADR titles and read only the matching one; comment mentions an API contract, read the relevant file in specs/<feature>/contracts/. Never reads a file "just in case." This matters because the alternative is loading every doc into context on every PR, which blows out the context window for nothing.
Why this beats prompting
The argument isn't that skills are faster, though they are. The argument is reproducibility, and it shows up in three places I care about:
- Across sessions. Same input, same shape of output, Monday or Friday. No more "I phrased it differently because I was tired."
- Across machines. My laptop and my desktop both sync
~/.claude/from a git repo. The vocabulary is identical on either side, so/doneon the desktop produces the same artifact set as/doneon the laptop. - Across teammates. When someone joins the project, they don't need to learn how I phrase prompts. They invoke
/review-planand get the same review I do, with the same verdict line in the same place.
Common pitfalls
A few things I got wrong before I got them right.
Writing descriptions as prose. My first attempt at /conventions had a description that read like a sentence: "Use this skill to keep your code conventions in sync." Claude never fired it. The description that works front-loads the trigger phrases and capabilities: "Given a code artifact (file or folder), find the matching technology conventions page in Confluence. If none exists, extract best practices and create one."
Forgetting disable-model-invocation on side-effect skills. /done and /fix-pr write commits, push branches, create PRs. If Claude can fire them autonomously based on a vague description match, you'll get a commit you didn't ask for. Setting disable-model-invocation: true means the skill only runs on explicit /done invocation.
Hard gates that aren't hard. Saying "ask the user first" doesn't gate anything. Saying "NEVER write to any file before the user answers this question" with the word NEVER in caps, the consequence spelled out, and the gate framed as a refusal rather than a suggestion — that gates. Negative space, again.
Skipping composition. If /teach and /search can't be chained, they're worth half of what they could be. Design the body of each skill to scope cleanly: /search is about source ranking and citation, /teach is about pedagogy. Either can run alone, both can run together, the order encodes intent.
What to build first
I'll close on the advice I'd give anyone starting their own vocabulary.
Don't start with /done. Don't start with /fix-pr. Start with a meta-skill: a skill whose job is to create other skills.
Mine is small. It asks me four questions (what should it do, when should it fire, what tools does it need, are there side effects), generates the SKILL.md with a well-formed description and a procedural body, and drops it in the right folder. Every subsequent skill I built took half the time because I wasn't reinventing the frontmatter or the gate pattern each time.
The meta-skill is the bootstrap. It's how the vocabulary becomes self-extending. Once you can author a skill in five minutes instead of fifty, the cost of naming a new mode drops below the cost of re-prompting for it, and the whole thing tips over into a workflow you actually live in.
Pick the friction you've felt three times this month. Give it a name. Give it a gate. Give it an output contract. That's a skill. Build the meta-skill that builds it. Then build the next one.
The day you reach for /review-plan the way you reach for git status, you're done. The vocabulary has eaten the prompts.